Extraia dados de qualquer site sem código com Firecrawl e n8n
Tutorial de web scraping para iniciantes: aprenda a extrair dados de qualquer site automaticamente com Firecrawl e n8n, sem escrever código. Passo a passo explicado.
Existe uma quantidade absurda de informação útil espalhada pela internet — preços de concorrentes, listas de produtos, artigos, dados públicos. O problema é que ela está presa dentro de páginas, feita para humanos lerem uma de cada vez. Copiar tudo na mão é inviável.
Web scraping é a técnica de extrair esses dados de forma automática. Sempre foi território de programador, porque exigia escrever código que entendesse a estrutura confusa de cada site. Não é mais. Com o Firecrawl e o n8n, você extrai dados de qualquer página e organiza num formato útil — sem escrever uma linha de código.
Neste tutorial você vai montar um fluxo que pega dados de um site e salva organizados, pronto para usar. Como sempre, parto do princípio de que você não programa, então cada conceito vem explicado.
O que é web scraping, em português claro
Imagine que você quer os preços de 50 produtos de uma loja. Você poderia abrir cada página, copiar o nome e o preço, e colar numa planilha. Cinquenta vezes. Web scraping faz isso automaticamente, em segundos.
Na prática, é um programa que:
Visita uma página da web
Lê o conteúdo
Extrai só a informação que interessa
Organiza num formato limpo (planilha, lista, banco de dados)
O desafio histórico era que cada site tem uma estrutura interna diferente e bagunçada. É aí que o Firecrawl muda o jogo.
Orquestra o fluxo: quando rodar, o que fazer com os dados
O Firecrawl resolve a parte difícil: ele acessa qualquer página e devolve o conteúdo já limpo, em formato que faz sentido — texto organizado ou até dados estruturados. Em vez do HTML bagunçado que um site normalmente entrega, você recebe a informação pronta para usar.
O n8n é onde você monta o fluxo visualmente, sem código: arrastar blocos, conectar com setas, definir quando roda.
O que é o n8n? É uma ferramenta de automação visual. Você monta "fluxos" conectando blocos que representam ações — sem programar. Se você leu nossos outros tutoriais sobre agentes, já viu o n8n em ação.
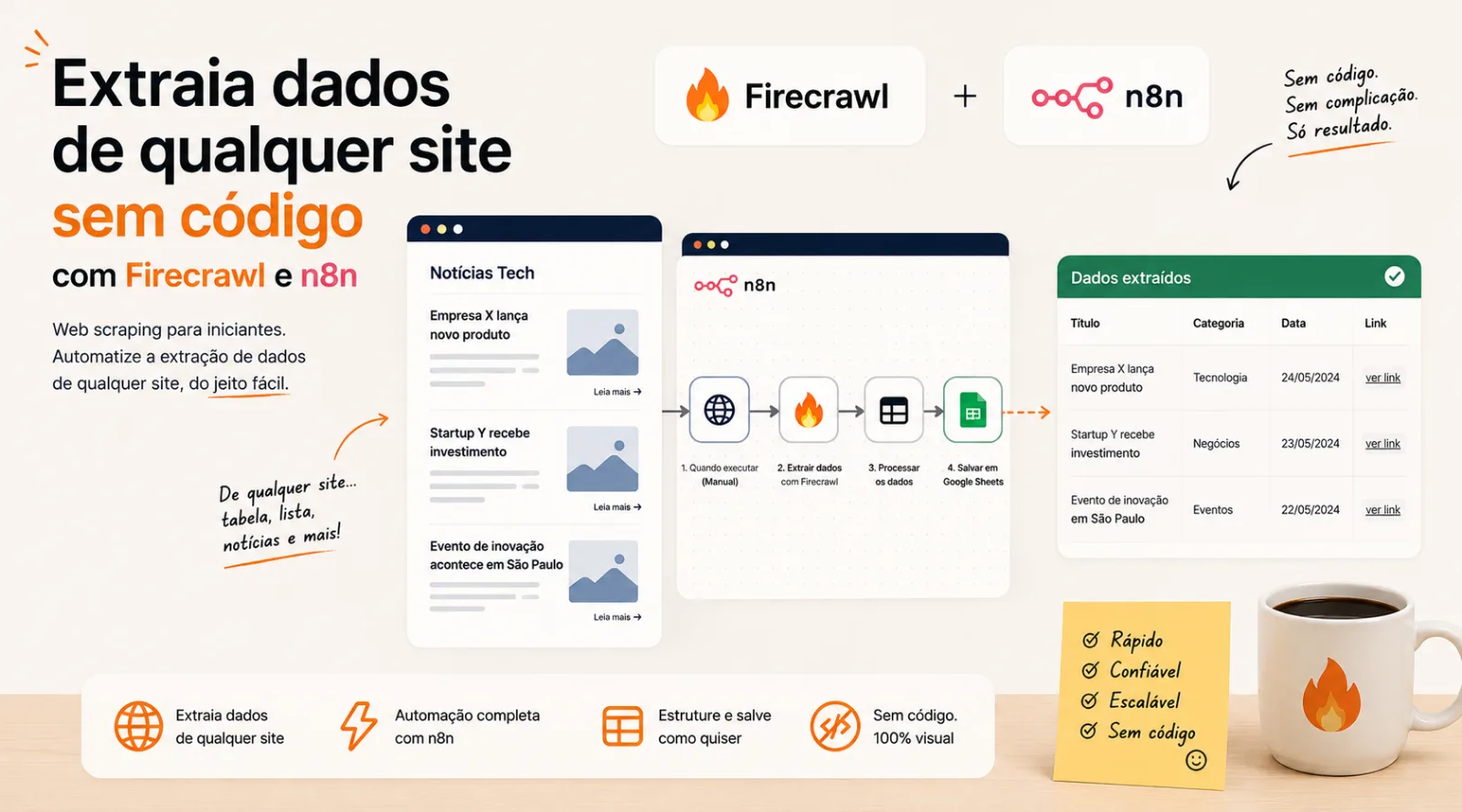
O que vamos construir
Um fluxo que extrai informações de uma página da web e salva organizadas numa planilha do Google Sheets. Você poderá adaptar para qualquer uso depois — monitorar preços, coletar artigos, montar listas.
Você define a página (ou lista de páginas)
↓
Firecrawl visita e extrai o conteúdo limpo
↓
n8n organiza os dados que interessam
↓
Salva tudo numa planilha do Google Sheets
Sobre custo: o Firecrawl tem um plano gratuito com cota mensal de páginas — suficiente para aprender e para projetos pequenos. O n8n é gratuito para self-hosted ou tem plano cloud acessível.
O que é uma chave de API de novo? É uma "senha" que permite o n8n conversar com o Firecrawl em seu nome. Cada serviço tem a sua. Nunca compartilhe.
Passo 2 — Teste o Firecrawl antes de automatizar
Antes de montar o fluxo, vale ver o Firecrawl funcionando. No próprio painel dele, existe uma área de teste (playground) onde você cola uma URL e vê o resultado.
Cole o endereço de qualquer página — um artigo de blog, uma página de produto — e veja o que ele devolve: o conteúdo limpo, organizado, sem menus, anúncios ou código no meio.
Isso te dá a intuição do que vai chegar no n8n. O Firecrawl faz a parte suja; você só decide o que fazer com o resultado limpo.
Passo 3 — Monte o fluxo no n8n
Abra o n8n e crie um workflow novo. Vamos adicionar os blocos (que o n8n chama de "nós") em sequência:
Manual Trigger (para testar rodando manualmente)
↓
HTTP Request (chama o Firecrawl)
↓
Edit Fields (organiza os dados extraídos)
↓
Google Sheets (salva na planilha)
Passo 4 — Configure a chamada ao Firecrawl
O bloco que conversa com o Firecrawl é o HTTP Request. Ele faz uma "requisição" — basicamente, manda um pedido para o Firecrawl e recebe os dados de volta.
Configure assim:
Campo
Valor
Method
POST
URL
endpoint de scrape do Firecrawl (veja na doc oficial)
Authentication
Header com sua API Key
Body
a URL que você quer extrair
O que é POST? É um tipo de pedido na web. "GET" é quando você só quer ler algo; "POST" é quando você manda informação junto (aqui, a URL que quer extrair). Não precisa decorar — o n8n te guia.
No corpo (Body) do pedido, você indica a página a extrair e, opcionalmente, pede dados estruturados. O Firecrawl tem uma funcionalidade poderosa: você descreve em linguagem natural o que quer extrair, e ele organiza nesse formato.
Por exemplo, para uma página de produto, você pode pedir:
Traduzindo: "visite essa URL e me devolva o nome do produto, o preço e a disponibilidade, organizados". O Firecrawl entende e devolve exatamente esses campos.
Passo 5 — Organize os dados extraídos
O bloco Edit Fields (também chamado de "Set" em versões do n8n) serve para pegar o que o Firecrawl devolveu e organizar nos campos que você quer salvar.
Aqui você mapeia: o nome_produto que veio do Firecrawl vai para a coluna "Produto" da planilha, o preco vai para a coluna "Preço", e assim por diante.
É um trabalho de "ligar os pontos" — visual, sem código. Você arrasta ou seleciona qual dado vai para qual lugar.
Passo 6 — Salve no Google Sheets
O bloco Google Sheets conecta sua conta Google e salva os dados numa planilha.
Crie uma planilha nova no Google Sheets com as colunas que você quer (ex: Produto, Preço, Data)
No n8n, no bloco Google Sheets, conecte sua conta Google
Escolha a planilha e a aba
Configure a operação como Append (adicionar uma nova linha)
Mapeie cada dado do passo anterior para a coluna correspondente
Agora, cada vez que o fluxo rodar, uma nova linha com os dados extraídos aparece na sua planilha.
Passo 7 — Teste o fluxo completo
Clique em Test Workflow no n8n e acompanhe:
O HTTP Request chamou o Firecrawl com sucesso?
Os dados voltaram organizados?
A linha apareceu na planilha do Google?
Se cada bloco ficar verde e a planilha receber os dados, está funcionando. Se algum bloco der erro, clique nele para ver a mensagem — geralmente é a chave de API ou um campo mapeado errado.
Passo 8 — Automatize de verdade
Até aqui você roda manualmente. Para o fluxo trabalhar sozinho, troque o bloco Manual Trigger por um Schedule Trigger, definindo a frequência:
Toda manhã às 8h
Uma vez por semana
A cada 6 horas
Para extrair várias páginas de uma vez, adicione um bloco que percorre uma lista de URLs — assim o Firecrawl processa todas em sequência e cada uma vira uma linha na planilha.
Casos de uso reais
Esse fluxo básico se adapta para muita coisa:
Uso
Como adaptar
Monitorar preços de concorrentes
Liste as URLs dos produtos, rode diariamente
Coletar artigos de um nicho
Extraia título e resumo de blogs do setor
Montar lista de leads
Extraia dados de diretórios de empresas
Acompanhar vagas de emprego
Extraia vagas de sites de carreira
Alimentar um projeto com dados
Extraia e jogue numa base do seu app
Cuidados importantes com web scraping
Web scraping é uma ferramenta poderosa, e com isso vêm responsabilidades:
Respeite os termos de uso dos sites. Alguns proíbem extração automática. Verifique antes de fazer scraping em escala.
Não sobrecarregue os servidores. Extrair milhares de páginas em segundos pode derrubar um site pequeno. O Firecrawl já controla o ritmo, mas use o bom senso.
Dados pessoais exigem cuidado. Coletar dados de pessoas envolve a LGPD no Brasil. Para dados públicos de produtos ou conteúdo, sem problema. Para dados pessoais, conheça as regras.
Sites mudam. Se um site muda a estrutura, sua extração pode parar de funcionar. A vantagem do Firecrawl com extração por descrição é que ele se adapta melhor a mudanças do que scraping tradicional.
O que isso muda na prática
Acesso a dados sempre foi uma vantagem competitiva — quem tem informação organizada toma decisões melhores. Antes, transformar a web num banco de dados estruturado exigia um programador. Hoje, qualquer pessoa monta um fluxo de extração numa tarde.
Para quem faz vibe coding, isso abre possibilidades concretas: alimentar um app com dados reais, monitorar um mercado, criar uma base de conteúdo. A informação que está espalhada pela internet vira matéria-prima para os seus projetos.
Conclusão
Você montou um fluxo de web scraping sem escrever código — algo que até pouco tempo exigia conhecimento técnico considerável. O Firecrawl cuida da parte difícil de ler e limpar as páginas, e o n8n orquestra tudo de forma visual.
Comece com uma página simples, veja os dados chegarem na planilha, e depois expanda para listas e automação agendada. A partir daí, toda vez que você pensar "queria ter esses dados organizados", vai saber que dá para extrair — e usar como combustível para o que você está construindo.
Tags
#web scraping#firecrawl#n8n#automação#extração de dados#tutorial#iniciante#scraping